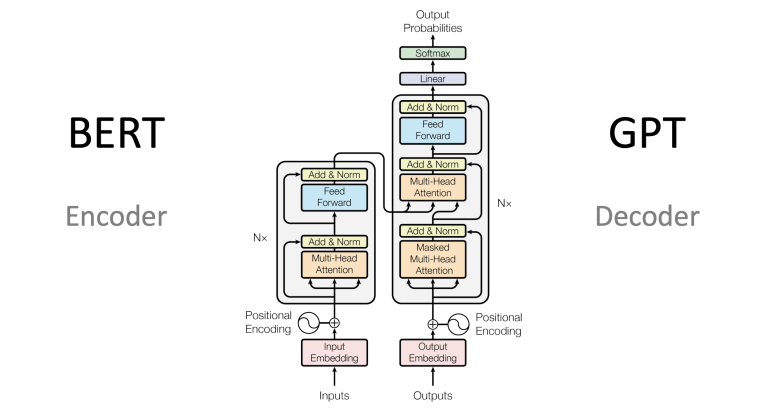
weqfajinaazad.org – Pengenalan suara (speech recognition) adalah teknologi yang memungkinkan perangkat untuk mengenali dan memproses ucapan manusia menjadi data digital yang dapat dipahami mesin. Teknologi ini telah menjadi bagian integral dari kehidupan sehari-hari, mulai dari asisten virtual seperti Siri dan Google Assistant hingga aplikasi transkripsi dan kontrol perangkat berbasis suara. Artikel ini akan membahas pengertian, sejarah, cara kerja, aplikasi, tantangan, dan masa depan teknologi pengenalan suara.
Apa Itu Pengenalan Suara?
Pengenalan suara adalah cabang dari kecerdasan buatan (AI) dan pemrosesan sinyal yang memungkinkan komputer untuk mengubah sinyal audio berupa ucapan manusia menjadi teks atau perintah. Sistem ini mengandalkan algoritma kompleks dan pembelajaran mesin (machine learning) untuk mengenali pola suara, aksen, dan kosakata. Teknologi ini tidak hanya mempermudah interaksi manusia-mesin, tetapi juga meningkatkan aksesibilitas bagi penyandang disabilitas.
Sejarah Singkat Pengenalan Suara
Perkembangan teknologi pengenalan suara telah melalui perjalanan panjang:
-
1950-an: Bell Laboratories menciptakan “Audrey”, sistem pengenalan suara pertama yang mampu mengenali angka yang diucapkan oleh satu orang.
-
1970-an: IBM dan Carnegie Mellon University mengembangkan sistem seperti “Harpy” yang dapat mengenali sekitar 1.000 kata.
-
1990-an: Dragon NaturallySpeaking memperkenalkan pengenalan suara berbasis PC dengan akurasi yang lebih baik.
-
2000-an: Kemajuan dalam pembelajaran mesin dan neural networks memungkinkan sistem seperti Siri (2011) dan Google Voice Search untuk menangani perintah yang lebih kompleks.
-
2020-an: Model AI seperti deep learning dan transformer (contohnya Whisper dari OpenAI) meningkatkan akurasi pengenalan suara hingga mendekati tingkat manusia, bahkan untuk berbagai bahasa dan aksen.
Cara Kerja Pengenalan Suara
Proses pengenalan suara melibatkan beberapa tahap utama:
-
Perekaman Suara: Mikrofon menangkap gelombang suara dari ucapan manusia dan mengubahnya menjadi sinyal digital.
-
Pra-pemrosesan: Sinyal audio dibersihkan dari noise dan dianalisis untuk mengekstrak fitur akustik, seperti frekuensi dan amplitudo.
-
Pengenalan Pola: Algoritma seperti Hidden Markov Models (HMM) atau neural networks membandingkan fitur suara dengan model bahasa dan akustik untuk mengenali kata atau frasa.
-
Pemrosesan Bahasa Alami (NLP): Sistem menerjemahkan kata-kata menjadi teks atau perintah dengan memahami konteks dan tata bahasa.
-
Output: Hasilnya berupa teks (untuk transkripsi) atau tindakan (misalnya, menyalakan lampu pintar).
Model modern menggunakan deep learning untuk meningkatkan akurasi, dengan pelatihan pada dataset besar yang mencakup berbagai bahasa, aksen, dan dialek.
Aplikasi Pengenalan Suara
Teknologi pengenalan suara telah diterapkan di berbagai bidang:
-
Asisten Virtual: Siri, Google Assistant, dan Alexa memungkinkan pengguna mengatur jadwal, mencari informasi, atau mengontrol perangkat pintar.
-
Transkripsi Otomatis: Digunakan dalam aplikasi seperti Zoom, Google Meet, atau Otter untuk mencatat rapat atau wawancara.
-
Aksesibilitas: Membantu penyandang disabilitas, seperti tunanetra atau pengguna dengan gangguan motorik, untuk berinteraksi dengan teknologi.
-
Otomotif: Sistem seperti Ford SYNC atau BMW Intelligent Personal Assistant memungkinkan pengemudi mengontrol navigasi atau panggilan tanpa tangan.
-
Layanan Pelanggan: Chatbot berbasis suara menangani pertanyaan pelanggan di call center.
-
Pendidikan: Alat seperti Duolingo menggunakan pengenalan suara untuk melatih pengucapan bahasa asing.
Tantangan dalam Pengenalan Suara
Meski telah berkembang pesat, teknologi ini masih menghadapi beberapa tantangan:
-
Aksen dan Dialek: Variasi pengucapan di berbagai wilayah dapat menurunkan akurasi.
-
Kebisingan Latar Belakang: Suara lingkungan, seperti keramaian atau angin, dapat mengganggu pengenalan.
-
Multibahasa: Sistem harus mampu menangani transisi antar bahasa dalam satu percakapan.
-
Privasi: Perekaman suara menimbulkan kekhawatiran tentang keamanan data dan penyadapan.
-
Konteks: Memahami makna kontekstual atau kalimat ambigu masih sulit bagi beberapa sistem.
Masa Depan Pengenalan Suara
Dengan kemajuan AI, pengenalan suara diperkirakan akan semakin��
System: Masa Depan Pengenalan Suara
Dengan kemajuan AI, pengenalan suara diperkirakan akan semakin canggih dan terintegrasi dalam berbagai aspek kehidupan. Berikut adalah beberapa tren masa depan teknologi ini:
-
Akurasi yang Lebih Tinggi: Model AI seperti transformer dan large language models akan terus meningkatkan kemampuan pengenalan suara untuk memahami aksen, dialek, dan bahasa yang lebih beragam dengan akurasi mendekati 100%.
-
Integrasi Multimodal: Pengenalan suara akan digabungkan dengan teknologi lain seperti pengenalan gambar dan gerakan untuk menciptakan interaksi yang lebih alami, misalnya dalam asisten virtual yang memahami konteks visual dan verbal.
-
Pengenalan Suara Real-Time Multibahasa: Sistem akan mampu menerjemahkan dan mengenali berbagai bahasa secara instan, mendukung komunikasi global yang lebih lancar.
-
Edge Computing: Pengenalan suara akan semakin banyak diproses secara lokal di perangkat (bukan di cloud) untuk meningkatkan kecepatan dan privasi, didukung oleh chip AI seperti NPU pada prosesor Snapdragon atau Intel Core Ultra.
-
Personalisasi: Sistem akan belajar dari kebiasaan pengguna untuk mengenali suara mereka dengan lebih baik, bahkan dalam kondisi bising atau dengan kosakata khusus.
-
Aplikasi Baru: Dari kesehatan (merekam catatan medis secara otomatis) hingga gaming (kontrol suara dalam permainan imersif), pengenalan suara akan memperluas cakupan penggunaannya.
Pengenalan suara telah berkembang dari eksperimen laboratorium menjadi teknologi yang ada di mana-mana, mengubah cara kita berinteraksi dengan perangkat, meningkatkan produktivitas, dan memperluas aksesibilitas. Meskipun tantangan seperti aksen dan privasi masih ada, kemajuan dalam deep learning dan perangkat keras AI menjanjikan masa depan yang lebih cerdas dan responsif. Dengan aplikasi yang terus berkembang, pengenalan suara akan tetap menjadi pilar utama dalam evolusi kecerdasan buatan, menjadikan komunikasi manusia-mesin lebih intuitif dan efisien.